
During the last week, I attended the Web Conference 2019 (#TheWebConf2019). I had a blast and the pleasure to meet and hang out with my perspective advisor in Switzerland, some future EPFL colleagues, some folks I befriended in social media, and an old friend. Moreover, and perhaps more importantly, I was able to share the research I did last summer in Switzerland with Bob and be exposed to some pretty cool stuff. The rest of this post is divided into sections with no apparent logic to it.
The #CyberSafety Workshop
 Content manipulation is no longer a synonym for spammer. It involves state sponsored agents and people trying to steer the directions communities go; Tyler Otto from Reddit.
Content manipulation is no longer a synonym for spammer. It involves state sponsored agents and people trying to steer the directions communities go; Tyler Otto from Reddit.
 We lack tools to trace how information spreads across different services; Gianluca from Boston University.
We lack tools to trace how information spreads across different services; Gianluca from Boston University.
 Barry, from the University of Illinois, shows how physics inspired models may help us get a better understanding of fringe communities on different levels.
Barry, from the University of Illinois, shows how physics inspired models may help us get a better understanding of fringe communities on different levels.
On the first day of the conference, I attended this cool workshop on Cybersafety. Although the name may evoke terms like malware and botnets, this was not was the workshop was about… Instead, it was mostly about social networks and fringe communities (which tells something about the current state of affairs in the world, hehe). Some key takeaways from the workshop for me was:
-
For some websites, like Reddit, we need to build tools that distribute moderation to the community at large while still having some central control.
-
Hate data is hard to label. There is disagreement (cultural or contextual), not to mention code-words and cryptic references.
-
Threats in cyberspace now include stuff like doxxing, crypto scams, cyberbullying, and conspiracy theories.
-
Online services do not exist in a vacuum, and to study things like hate speech, we may need to look at multiple platforms and not just one.
-
Data-driven approaches can complement traditional hate-speech watchdogs by surfacing hate and broadening our understanding of the phenomena.
The #WikiWorkshop2019

On the second day, I attended the equally fabulous Wiki Workshop. It was the first Wiki-centric event I ever attended, and I enjoyed the work presented and the spirit of the community working around Wikipedia. A highlight for me was Denny Vrandečić’s talk on what is beyond Wiki Data (Wikipedia’s Knowledge Graph). One of the ways Denny proposes to bring knowledge to more individuals (and to more languages) is to create this idea of constructors and renderers:
-
A constructor would be formalized description of some information in Wikipedia. For example, an election (whose description could involve candidates, number of votes per candidate, and a winner).
-
A renderer would be a realization of this constructor in natural language. Each language would have its renderer.
Together, these things would allow the information stored in the Knowledge graph of wiki-data to be rendered as text across many languages. Moreover, it seemed like a clever way to avoid unnecessary work, as creating these renderers would be much more straightforward than creating multiple texts.
Day #1
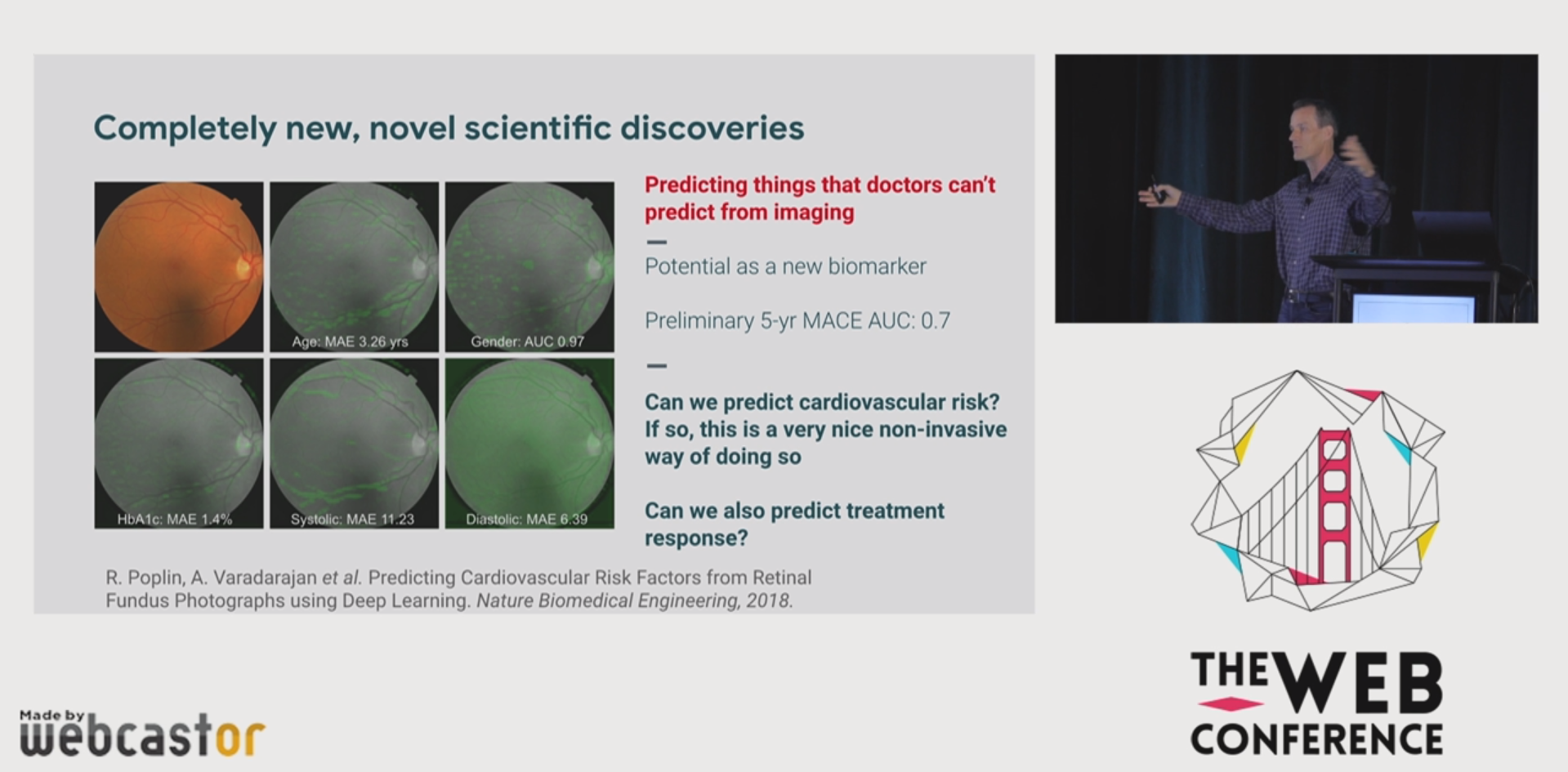 I wish I had more on Web-related AI stuff, but you gotta give google some credit for their achievements in ML for medicine…
I wish I had more on Web-related AI stuff, but you gotta give google some credit for their achievements in ML for medicine…
The first keynote at the conference was by Jeff Dean, from Google. In his talk, I had a feeling I was being exposed to pretty much everything NIPS-related that Google had done in the last 5 years. While the stuff Google did is doubtlessly great, I was left wondering about the “questions not answered” by the keynote… Google is probably one of the biggest deployers of socio-technical systems globally. While a retrospective on ML-related advancements is great, I’d rather have listened more about Google’s vision on how these technologies may be employed in the future.
Also, on the first day, two papers that stood out for me were:
-
(Mis)Information Dissemination in WhatsApp: Gathering, Analyzing and Countermeasures — there, a bunch of folks, mainly from UFMG, give us some insights on the problem of misinformation on WhatsApp… It is very important work, and I think it points to the direction of trying to detect coordinated efforts to disseminate misinformation on the world’s #1 unintended social network.
-
What happened? The Spread of Fake News Publisher Content During the 2016 U.S. Presidential Election — A single-authored paper by Ceren Bundak. What I liked about the paper was that it (a) analyzed interesting aspects of fake news; namely: prevalence, topic & alignment, and (b) was written in a very cautious manner, being very clear about the ups and downs of the analyses and the data collection process.
Day #2

During the second day of the conference, a special event was held to discuss the future of the open web. It was a unique event in that it included journalists, lawyers, and even a member of the EU parliament. The atmosphere of the talks ranged from rather grim — with a journalist talking on political threats to the open web — to quite optimistic, with Brewster Kahle, founder of the internet archive, advocating for a new decentralized internet (for example, this website). If on monday I had a display of the harms that have flourished in the the anarchy and the anonymity of the open web, on Wednesday I was reminded of its benefits. An excellent mantra I got from the talks from David Keye’s talk was that:
“companies moderate, governments regulate.”
This may sound borderline obvious, but it encompasses many problems that the web currently has. On the one hand, issues like the ones approached in the #Cybersafety workshop have a lot to do with how companies moderate content: for example, allowing hateful content from fringe communities like gab and 4chan to bleed into their platforms. On the other, you have all these problems that arise when governments over-regulate the internet, which may, for example, compromise one’s freedom of speech and access to information. Also, the question of what government should regulate and what companies should moderate is fascinating.
Day #3
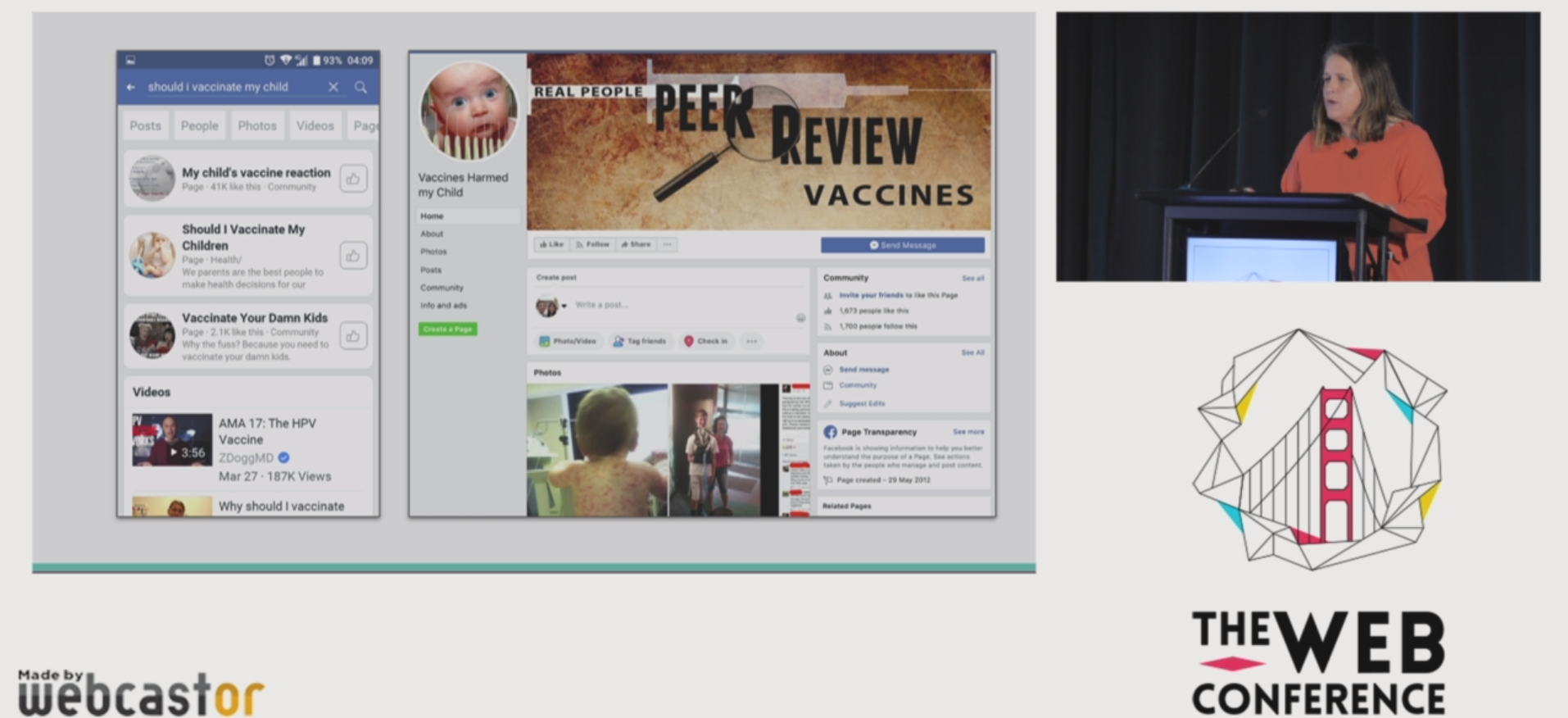 Claire Wardle claims that we should try to understand these communities and people rather than provide them with more information (which they already have, but choose to ignore).
Claire Wardle claims that we should try to understand these communities and people rather than provide them with more information (which they already have, but choose to ignore).
We had a keynote by Claire Wardle, a TED fellow in the third day. Claire’s keynote included excellent discussions on the web information environment, deep fakes, how misinformation reaches professional media, and different types of misinformation. A focus she gave that was refreshing to me was the idea of educating the public on dealing with fake news. It is a task that is most likely necessary, yet, it is hard and often conflated with politics. Moreover, there is not a clear path on how to do it… Maybe we should be doing more research on that?
Also, on that day, a paper that stood out to me was Generalists and Specialists: Using Community Embeddings to Quantify Activity Diversity in Online Platforms. In the paper, Isaac and Ashton had this cool idea of understanding two different user patterns on Reddit, generalists (who would post in many communities from varied topics) and specialists (who would focus on some topic). Noteworthy findings include that specialists engage more but for fewer times in Reddit and are the ones making great comments. Moreover, they came up with this single metric to analyze users and communities in that spectrum, which they named the GS-score.
My poster
 Me presenting my pretty nice looking poster.
Me presenting my pretty nice looking poster.
On Wednesday, I presented my work on message distortion in information cascades. The paper is a fun crowdsourced experiment. We asked crowd workers to summarize medical abstracts in two settings: looking at the original text (duh) and iteratively, as in a telephone game. With this data, we can separate two effects that make info gets distorted in cascades: summarization and word-of-mouth. We found some clever ways of tracking information, and it turns out the telephone effect exists, and it impacts the most critical information the most (e.g., the conclusions of the abstract). However, the effect has its nuances, and good intermediate summaries may lead to improvements compared to the control setting. To read more about this and about some observational findings we had on summarization (e.g., what strategies perform better?) check out the paper :).