Recentemente o Átila Iamarino (@oatila), que dispensa apresentações nessa altura do campeonato, me marcou em uma postagem do Sleeping Giants Brasil (@slpng_giants_pt), uma iniciativa muito bacana que está tentando cortar o problema da desinformação pela raiz, diminuindo os benefícios financeiros desse tipo de “empreitada”. Se você quiser pode ver a thread original aqui, mas a pergunta que foi feita, abstraindo um pouco o contexto, pode ser expressada como:
Será que conseguiríamos medir o impacto da desinformação na saúde pública?
Depois de dar minha opinião na madrugada (estou fazendo meu doutorado na Suíça), acordei pensando sobre o assunto e decidi me alongar mais um pouco sobre ele. Acho que isso é um exemplo muito bacana para discutir estudos experimentais (onde os pesquisadores cuidadosamente desenham uma intervenção) e observacionais (com dados que já existem), e também falar das limitações e das dificuldades de fazer pesquisa misturando o mundo real e o virtual. Como essa postagem trata de um assunto muito sério, vale um disclaimer: eu não sou médico, sou um doutorando em computação que mexe com redes sociais e estudos observacionais. Sei sobre causalidade e estatística, mas o que eu estou escrevendo aqui é mais uma série de pensamentos incompletos do que um plano rigoroso para um estudo.
A rota experimental
Num mundo hipotético, poderíamos fazer esse estudo da desinformação com um experimento controlado. Por exemplo, escolheríamos participantes completamente ao acaso, e para uma metade (o grupo de tratamento) dos participantes mandaríamos notícias falsas e pra outra metade (o grupo controle), notícias verdadeiras. Então poderíamos medir, para cada uma das duas populações, qual foi a taxa de incidência do coronavírus, o número de mortes, etc. Essa abordagem não é possível pois acarreta um grande problema ético: estaríamos expondo uma parcela da população a potenciais riscos de saúde.
Outra abordagem possível seria tentar usar intervenções para reduzir o impacto de notícias falsas. Então ao invés de enviar notícias falsas para os candidatos, enviaríamos informação confiável e que desmente notícias falsas para o grupo tratamento, e nada para um grupo controle.
Suponha por exemplo que fizéssemos o experimento descrito com uma população demograficamente diversa, escolhendo aleatoriamente quem ia pro grupo de tratamento, e quem ia pro grupo controle. Suponha também que tenhamos observado menor incidência de COVID-19 no grupo tratamento. Podemos expressar nossa hipótese com um grafo causal (um termo complicado para setinhas e bolinhas que implicam causalidade):
 Modelo 1: o mais simples possível!
Modelo 1: o mais simples possível!
Contudo, isso não é exatamente o que queríamos estudar inicialmente. Acho que esse estudo seria interessante por si só, mas vamos voltar à questão inicial. Queríamos estudar o efeito da desinformação, e isso não está nesse modelo! Um modelo que englobaria isso seria:
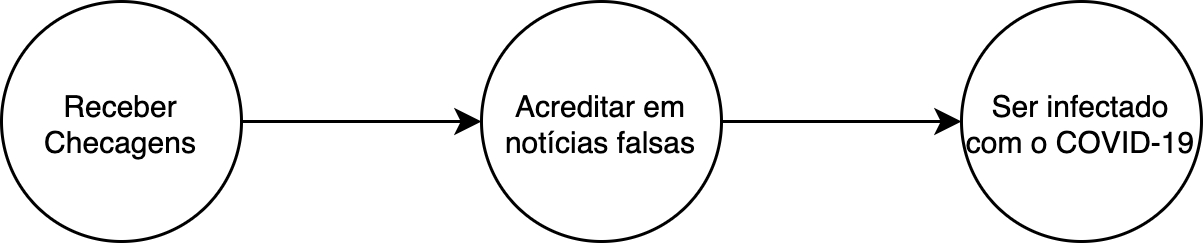 Modelo 2: note que queremos mesmo é estudar a variável mediadora!
Modelo 2: note que queremos mesmo é estudar a variável mediadora!
Ou seja, as notícias mudam a suscetibilidade das pessoas à desinformação, que por sua vez aumentaria a chance de um individuo ser infetado pelo coronavírus. A gente chama essa nova variável de variável mediadora (mediator variable).
Nosso modelo está claramente incompleto, pois existem diversas coisas que influenciam tanto a desinformação quanto a chance de alguém contrair o COVID-19. Por exemplo, provavelmente a idade influência tanto no tipo de conteúdo que você recebe no Whatsapp quanto no seu risco de contrair o coronavírus. Essas variáveis são chamadas de cofatores (confounders). Vamos representar a existência dessas variáveis como uma linha pontilhada entre “Acreditar em notícias falsas” e “Ser infectado com o COVID-19”:
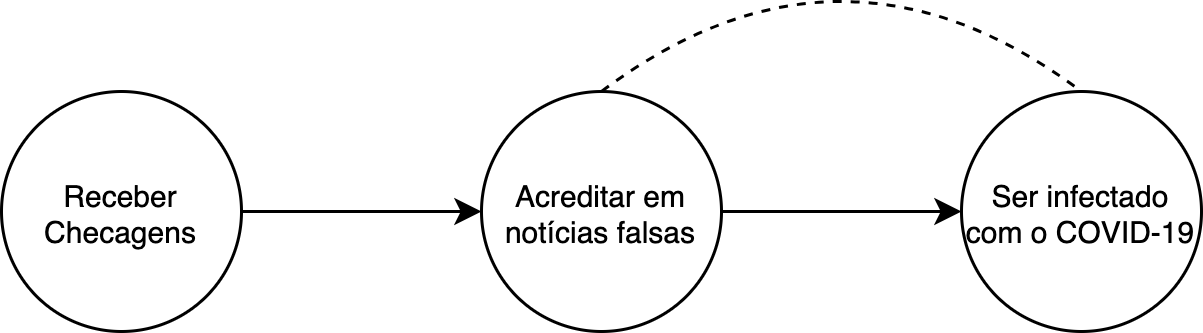 Modelo 3: A linha tracejada representa co-fatores!
Modelo 3: A linha tracejada representa co-fatores!
No nosso cenário não existe nenhum co-fator entre “Receber checagens” e “Acreditar em notícias falsas”, porque as checagens estão sendo mandadas aleatóriamente para metade da populacão! A exclamação não é àtoa, pois essa estrutura de grafo que acabamos de ver é particularmente amena à inferência causal. Podemos dizer que “Receber checagens” é um instrumento, e existem técnicas para medir a influência de “Acreditar em notícias falsas” e, “Ser infectado com o COVID-19” usando essa terceira variável.
Contudo, a parte triste da história é que teríamos de conseguir primeiro estudar o impacto das checagens no consumo de desinformação dos indivíduos. Sinceramente, não sei exatamente como isso poderia ser feito, pois esse impacto é extremamente subjetivo. Por exemplo, poderíamos coletar todos os links vistos por cada participante (que já é algo bem improvável de se conseguir) e contar quantas fake news cada pessoa viu. Além do fato de que isso é extremamente difícil de se obter por motivos de privacidade e que o processo envolveria classificar centenas de notícias como verdadeiras ou falsas, pode ser que mesmo com as checagens a pessoa continue recebendo desinformação, só que ela não acredita nela mais.
Além disso, pode ser que as checagens não adiantem muito! Isso não é tão absurdo de se considerar, pois existem estudos que mostram o efeito “tiro pela culatra” (backfire effect) onde tentar corrigir crenças falsas mas enraizadas pode acabar as reforçando [1] (Note que existem outros estudos que reproduziram [2] e disputaram esse efeito [3]). Nesse caso a variável instrumental “Receber checagens” seria o que é chamado de um instrumento fraco, e o estudo seria prejudicado…
Por fim, vale ressaltar que é preciso considerar eticamente se esse estudo é aceitável. Afinal, ao fazer esse estudo, estamos conscientemente deixando de dar informação a uma fração dos participantes! Por essas dificuldades, talvez seria interessante fazer um estudo observacional, isso é onde não fazemos uma intervenção, mas tentamos pegar dados que já existem e aprender algo com eles!
Fica pra próxima!