Este é o segundo post com algumas idéias sobre como alguém poderia estudar o impacto da desinformação na atual pandemia. Para ser bem justo, acho que o tema principal deste post e o anterior é falar sobre causalidade e experimentação. Nesse post especificamente, vamos falar sobre técnicas como “simular” o experimento com dados observacionais.
Anteriormente, discutimos alguns problemas associados à realização de experimentos relacionados com #fakenews. Aqui, voltamos à abordagem observacional, ou seja, onde o processo de geração de dados não foi cuidadosamente desenvolvido pelo persquisador. Como este post trata de um assunto muito sério, vale a pena um aviso: Eu não sou médico ou epidemiologista, sou um doutorando em Ciência da Computação que trabalha com redes sociais e estudos observacionais. Eu sei sobre causalidade e estatística, mas não sobre remédios, virologia ou saúde pública. O único projeto em que estive envolvido em saúde serviu apenas para me fazer perceber o quanto sou ignorante. O que estou escrevendo aqui é mais uma série de pensamentos incompletos do que uma direção rigorosa de pesquisa.
A Abordagem Observacional
Nessa abordagem, uma grande vantagem é que nos somos capazes de rastrear desinformação usando quaisquer métodos disponíveis (por exemplo, com a ajuda de um fact-checker). Podemos pré-selecionar postagens conhecidamente falsas e, que no nosso caso específico, minimizem o risco da pandemia ou os benefícios do distanciamento social e depois vincular esses dados ao mundo real. Ou seja, teríamos vincular essas notícias a indivíduos (e depois encontrar quem contraiu o vírus), ou alternativamente, vincular esses dados a regiões geográficas (para as quais temos estatísticas agregadas).
Uma vez com esses dois dados na mão, teríamos de ter certeza de que estamos realmente examinando a influência da desinformação na pandemia, controlando pra possíveis cofatores. Vamos supor que estamos fazendo o estudo no contexto do Twitter no Brasil. Isto é, a gente mede retuítadas em notícias falsas e (milagrosamente) conseguimos achar um grande número de usuários geo-localizatios que foram expostos à desinformação. A gente então conseguiria construir dois mapas: um coletado por autoridades públicas sobre a evolução da doença, e o outro coletado por nós, mostramos como a doença circulou no Twitter.
 Examplo de dados geográficos disponíveis sobre o COVID-19. Fonte: Uol
Examplo de dados geográficos disponíveis sobre o COVID-19. Fonte: Uol
A questão agora é: se compararmos esses dois mapas, quais poderiam ser os problemas de nossa análise? Vamos supor que os dados coletados pelas autoridades de saúde não sejam enviesados e vamos nos concentrar por um momento no viés presente no conjunto de dados que nós coletamos. Simplificando, o grande problema aqui é: “Quem usa o Twitter no Brasil?” Claramente, o uso não é distribuído uniformemente por toda a população. Por exemplo, é bem possível que os usuários da plataforma sejam mais jovens, mais ricos e mais instruídos do que a média da população brasileira. Além disso, é provável que pertençam a regiões mais urbanizadas do Brasil, onde o acesso a a internet é mais amplo.
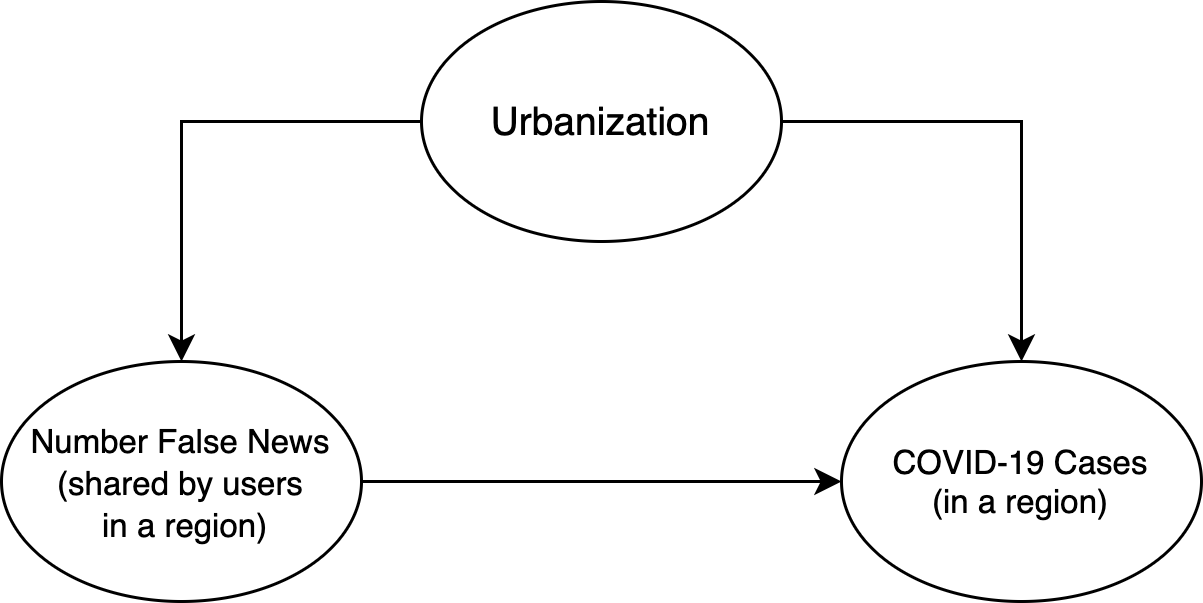 O modelo mais simples possível!
O modelo mais simples possível!
Ok, mas por que isso importa? Vamos considerar a mais ultima fonte de viés, a urbanização. Pode muito bem ser que as regiões mais urbanizadas é aonde há o maior número de infecções da doença (uma vez que se trata de um pandemia, e que densidade populacional provavelmente desempenhará um papel no contágio da mesma). Se tentarmos modelar isso (no nível geográfico) com um gráfico causal (veja acima), isso significa que a “urbanização” pode influenciar o “engajamento com desinformação” e o “número de infecções por COVID-19”.
Portanto, se ingenuamente medirmos o “engajamento com desinformação” e o correlacionarmos com o “número de Infecções por COVID-19 ”, podemos estar de fato observando forte correlação em regiões altamente urbanizadas e baixa correlação em áreas mais rurais. Isso significa que qualquer análise realizada teria que controlar esse cofator (e muitos outros).
Outros problemas que vale a pena mencionar aqui incluem:
-
É difícil modelar a pandemia, pois o número de pessoas infectadas cresce exponencialmente. Assim, precisaríamos comparar cuidadosamente as regiões de interesse. Por exemplo, a doença chegou às zonas rurais muito depois de ter chegado nas grandes cidades do Brasil, e seria injusto comparar um dos primeiros lugares a relatar casos com outra região que só teve o primeiro caso semanas depois.
-
Também no mesmo espírito, lugares diferentes implementaram intervenções não-farmacêuticas (por exemplo, lockdowns) em momentos diferentes, e estes precisam ser levados em consideração ao fazer o modelo. Seria injusto comparar um cidade em confinamento total com uma cidade onde não há intervenções de distanciamento social.
-
Por fim, alguém que está fazendo a análise precisa ter cuidado com os efeitos spillover. Ou seja, o “tratamento” que nós estamos estudando (aqui “engajamento com desinformação”) pode causar efeitos em regiões vizinhas regiões. Isso é perigoso, porque podemos subestimar o efeito calculado, dada a interconectividade de muitas regiões.
Dadas essas questões, alguns conselhos para o hipotético pesquisador que faz essa pesquisa seriam:
- Usar o “Engajamento relativo com desinformação no Twitter”, que provavelmente poderia explicar os diferentes níveis de uso do Twitter;
- Modelar de alguma forma o “aumento de R0” como resultado, e não o total de “número de infecções por COVID-19”. Isso poderia tornar mais justa a comparação entre cidades em diferentes estágios da pandemia.
- Tentar realizar a análise com regiões distantes umas das outras e suficientemente grandes para que os efeitos spillover sejam pequenos.
No geral, essa discussão ilustra muito bem por que é difícil apresentar boas análises observacionais! É um exercício constante de tentar criar um modelo, criticar esse modelo e, em seguida, tentar encontrar uma maneira de escapar inteligentemente dos problemas que você identificou. Depois de escrever um pouco sobre isso, sinceramente não sei se é possível fazer uma boa análise do impacto da desinformação com os dados disponíveis (ou pelo menos os dados que presumo estarem disponíveis).